







 11.05.00
11.05.00
 AGIANZA
AGIANZA

Sudah menjadi kemampuan natural manusia dalam memahami apa yang kita lihat, contohnya, saat kita melihat gambar di bawah ini, kita dapat dengan mudah mengidentifikasi objek-objek yang ada dalam gambar di bawah ini, beserta dengan hierarki nya.

Convolutional Neural Network (CNN) adalah salah satu jenis neural network yang biasa digunakan pada data image. CNN bisa digunakan untuk mendeteksi dan mengenali object pada sebuah image. CNN adalah sebuah teknik yang terinspirasi dari cara mamalia — manusia, menghasilkan persepsi visual seperti contoh diatas.
Secara garis besar Convolutional Neural Network (CNN) tidak jauh beda dengan neural network biasanya. CNN terdiri dari neuron yang memiliki weight, bias dan activation function. Convolutional layer juga terdiri dari neuron yang tersusun sedemikian rupa sehingga membentuk sebuah filter dengan panjang dan tinggi (pixels).
Bagaimana CNN bekerja?
Secara garis besarnya, CNN memanfaatkan proses konvolusi dengan menggerakan sebuah kernel konvolusi (filter) berukuran tertentu ke sebuah gambar, komputer mendapatkan informasi representatif baru dari hasil perkalian bagian gambar tersebut dengan filter yang digunakan.

Langkah 1 : Memecah gambar menjadi gambar yang lebih kecil yang tumpang tindih
Dari gambar seorang anak kecil yang menaiki kuda mainan diatas, hasil dari proses konvolusi dapat diilustrasikan sebagai berikut ini:

Dengan ini, gambar asli dari seorang anak kecil diatas menjadi 77 gambar yang lebih kecil dengan konvolusi yang sama.
Langah 2 : Memasukkan setiap gambar yang lebih kecil ke small neural network
Setiap gambar kecil dari hasil konvolusi tersebut kemudian dijadikan input untuk menghasilkan sebuah representasi fitur. Hal ini memberikan CNN kemampuan mengenali sebuah objek, dimanapun posisi objek tersebut muncul pada sebuah gambar.

Proses ini dilakukan untuk semua bagian dari masing-masing gambar kecilnya, dengan menggunakan filter yang sama. Dengan kata lain, setiap bagian gambar akan memiliki faktor pengali yang sama, atau dalam konteks neural network disebut sebagai weights sharing. Jika ada sesuatu yang tampak menarik di setiap gambarnya, maka akan ditandai bagian itu sebagai object of interest.
Langkah 3 : Menyimpan hasil dari masing-masing gambar kecil ke dalam array baru
Maka akan terlihat seperti ini:

Langkah 4 : Downsampling
Pada langkah 3, array masih terlalu besar, maka untuk mengecilkan ukuran array nya digunakan downsampling yang penggunaannya dinamakan max pooling atau mengambil nilai pixel terbesar di setiap pooling kernel. Dengan begitu, sekalipun mengurangi jumlah parameter, informasi terpenting dari bagian tersebut tetap diambil.

Langkah 5 : Membuat prediksi
Sejauh ini, kita telah merubah dari gambar yang berukuran besar menjadi array yang cukup kecil. Nah, array merupakan sekelompok angka, jadi dengan menggunakan array kecil itu kita bisa inputkan ke dalam jaringan saraf lain. Jaringan saraf yang paling terakhir akan memutuskan apakah gambarnya cocok atau tidak. Untuk memberikan perbedaan dari langkah konvolusi, maka bisa kita sebut dengan “fully connected” network.
Secara garis besarnya, langkah-langkah diatas tampak seperti gambar berikut ini :

— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — —
Arsitektur dari CNN dibagi menjadi 2 bagian besar, Feature Extraction Layer dan Fully-Connected Layer (MLP).


Feature Extraction Layer
Proses yang terjadi pada bagian ini adalah melakukan “encoding” dari sebuah image menjadi features yang berupa angka-angka yang merepresentasikan image tersebut (Feature Extraction). Feature extraction layer terdiri dari dua bagian yaitu Convolutional Layer dan Pooling Layer. Namun kadang ada beberapa riset/paper yang tidak menggunakan pooling.
Convolutional Layer (Conv. Layer)
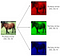
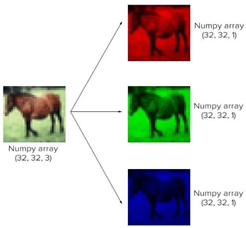
Gambar tersebut menunjukkan RGB (Red, Green, Blue) gambar berukuran 32x32 pixel yang sebenarnya adalah multidimensional array dengan ukuran 32x32 pixel (3 adalah jumlah channel). Convolutional layer terdiri dari neuron yang tersusun sedemikian rupa sehingga membentuk sebuah filter dengan panjang dan tinggi (pixel). Sebagai contoh , layer pertama pada feature extraction layer adalah conv. layer dengan ukuran 5x5x3. Panjang 5 pixel, tinggi 5 pixel, dan tebal/jumlah 3 buah sesuai dengan channel dari gambar tersebut.
Ketiga filter ini akan digeser keseluruhan bagian dari gambar. Setiap pergeseran akan dilakukan operasi “dot” antara input dan nilai dari filter tersebut sehinga menghasilkan sebuah output atau biasa disebut sebagai actvation map atau feature map. Proses dari feature map seperti pada gambar berikut.

Stride
Stride adalah parameter yang menentukan berapa jumlah pergeseran filter. Jika nilai stride adalah 1, maka conv. filter akan bergeser sebanyak 1 pixel secara horizontal lalu vertical. Pada ilustrasi diatas, stride yang digunakan adalah 2. Semakin kecil stride maka akan semakin detail informasi yang kita dapatkan dari sebuah input, namun membutuhkan komputasi yang lebih jika dibandingkan dengan stride yang besar. Namun perlu diperhatikan bahwa dengan menggunakan stride yang kecil kita tidak selalu akan mendapatkan performa yang bagus.
Padding
Padding atau zero padding adalah parameter menentukan jumlah pixel (berisi nilai 0) yang akan ditambhakan di setiap sisi dari input. Hal ini digunakan dengan tujuan untuk memanipulasi dimensi output dari conv. layer (feature map).
Dengan menggunakan padding, kita akan dapat mengukur dimensi output agar tetap sama seperti dimensi input atau setidaknya tidak berkurang secara drastis. Sehingga kita bisa menggunakan conv. layer yang lebih dalam sehingga lebih banyak feature yang berhasil di-extract. Meningkatkan performa model karena conv. layer akan fokus pada informasi yang sebenarnya yaitu yang berada diantara zero padding tersebut. Pada ilustrasi diatas, dimensi dari input sebenarnya adalah 5x5, jika dilakukan convolution dengan filter 3x3 dan stride sebesar 2, maka akan didaptkan feature map dengan ukuran 2x2. Namun jika ditambahkan zero padding sebanyak 1, maka feature map yang dihasilkan berukuran 3x3 (lebih banyak informasi yang dihasilkan). Untuk menghitung dimensi dari feature map kita bisa gunakan rumus sebagai berikut.
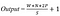
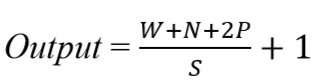
Keterangan :
W = Panjang/Tinggi Input
N = Panjang/Tinggi Filter
P = Zero Padding
S = Stride
Fungsi Aktivasi
Fungsi aktivasi berada pada tahap sebelum melakukan pooling layer dan setelah melakukan proses konvolusi. Pada tahap ini, nilai hasil konvolusi dikenakan fungsi aktivasi atau activation function. Terdapat beberapa fungsi aktivasi yang sering digunakan pada convolutional network, di antaranya tanh() atau reLU. Aktivasi reLU menjadi pilihan bagi beberapa peneliti karena sifatnya yang lebih berfungsi dengan baik.
Fungsi yang digunakan untuk aktivasi pada reLU, fungsi reLU adalah nilai output dari neuron bisa dinyatakan sebagai 0 jika inputnya adalah negatif. Jika nilai input dari fungsi aktivasi adalah positif, maka output dari neuron adalah nilai input aktivasi itu sendiri.
Pooling Layer
Polling layer biasanya berada setelah conv. layer. Pada prinsipnya pooling layer terdiri dari sebuah filter dengan ukuran dan stride tertentu yang bergeser pada seluruh area feature map. Pooling yang biasa digunakan adalah Max Pooling dan Average Pooling. Tujuan dari penggunaan pooling layer adalah mengurangi dimensi dari feature map (downsampling), sehingga mempercepat komputasi karena parameter yang harus di update semakin sedikit dan mengatasi overfitting.
Hal terpenting dalam pembuatan model CNN adalah dengan memilih banyak jenis lapisan pooling. Hal ini dapat menguntungkan kinerja model (Lee, Gallagher, & Tu, 2015). Lapisan pooling bekerja di setiap tumpukan feature map dan mengurangi ukurannya. Bentuk lapisan pooling yang paling umum adalah dengan menggunakan filter berukuran 2x2 yang diaplikasikan dengan langkah sebanyak 2 dan kemudian beroperasi pada setiap irisan dari input. Bentuk seperti ini akan mengurangi feature map hingga 75% dari ukuran aslinya. Berikut gambar contoh operasi Max Pooling.

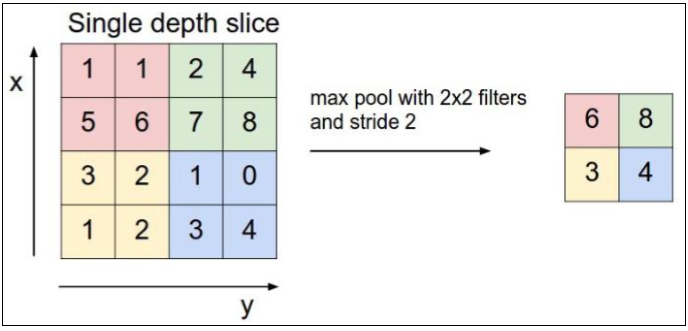
Lapisan pooling akan beroperasi pada setiap irisan kedalaman volume input secara bergantian. Pada gambar di atas, lapisan pooling menggunakan salah satu operasi maksimal yang merupakan operasi yang paling umum. Gambar 3.4. menunjukkan operasi dengan langkah 2 dan ukuran filter 2x2. Dari ukuran input 4x4, pada masing-masing 4 angka pada input operasi mengambil nilai maksimalnya dan membuat ukuran output baru menjadi 2x2.
Ilustrasi Proses pada Lapisan Konvolusi
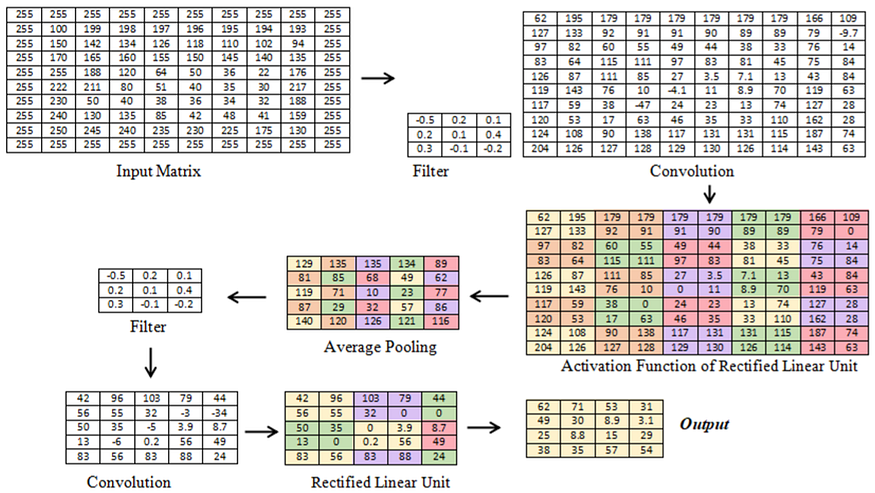
Lapisan konvolusi yang diaplikasikan untuk mendapatkan feature map. Contoh proses konvolusi dengan input berupa citra satu channel digambarkan seperti pada gambar berikut. Pada gambar tersebut, sebuah citra berukuran 10x10 piksel direpresentasikan sebagai matriks. Matriks awal diproses dengan dua layer konvolusi untuk mendapatkan feature map. Pada layer konvolusi pertama, filter yang digunakan berukuran 3x3 dengan bobot yang telah ditentukan. Hasil dari konvolusi pertama berupa matriks dengan ukuran 9x9.
Setelah melalui proses konvolusi, fungsi aktivasi dikenakan pada hasil konvolusi. Fungsi aktivasi yang digunakan adalah reLu. Output dari fungsi reLu kemudian dikenakan pooling dengan filter berukuran 2x2 dan stride sebesar dua. Sebelum melakukan pooling, dapat digunakan zero padding sehingga matriks hasil pooling berukuran 5x5. Matriks ini kemudian melalui tahap konvolusi kedua dengan ukuran filter sama seperti sebelumnya, tetapi dengan bobot yang berbeda. Dalam hal ini, ukuran tidak harus sama dengan konvolusi tahap pertama dan merupakan parameter yang bisa dioptimalkan. Sementara bobot matriks merupakan nilai yang dicari melalui proses pembejalaran.
Output dari proses konvolusi tahap kedua dikenakan dengan fungsi aktivasi yang sama, yaitu reLu. Pooling yang dikenakan berukuran 2x2 dengan stride satu, sehingga menghasilkan matriks dengan ukuran 4x4. Proses konvolusi bisa dilanjutkan sesuai dengan matriks akhir yang diinginkan. Dalam hal ini, jika konvolusi dihentikan sampai tahap kedua, maka matriks berukuran 4x4 tersebut menjadi input bagi neural network. Jika filter yang digunakan sejumlah n, maka input bagi neural network adalah nx4x4 nodes. Pada praktiknya, penggunaan fungsi aktivasi dan pooling bisa dibalik urutannya tanpa mengubah hasil dari konvolusi. Pembalikan ukuran ini bertujuan untuk mengurangi proses yang digunakan sehingga menjadi lebih cepat.

Fully-Connected Layer (MLP)
Feature map yang dihasilkan dari feature extraction masih berbentuk multidimensional array, sehingga harus melakukan “flatten” atau reshape feature map mejadi sebuah vector agar bisa digunakan sebagai input dari fully-connected layer.
Lapisan Fully-connected adalah lapisan dimana semua neuron aktivitas dari lapisan sebelumnya terhubung semua dengan neuron di lapisan selanjutnya seperti hal nya jaringan syaraf tiruan bisa. Setiap aktivitas dari lapisan sebelumnya perlu diubah menjadi data satu dimensi sebelum dapat dihubungkan ke semua neuron di lapisan Fully-Connected.
Lapisan Fully-Connected biasanya digunakan pada metode Multi lapisan Perceptron dan bertujuan untuk mengolah data sehingga bisa diklasifikasikan. Perbedaan anatar lapisan Fully-Connected dan lapisan konvolusi biasa dalah neuron di lapisan konvolusi terhubung hanya ke daerah tertentu pada input. Sementara lapisan Fully-Connected memiliki neuron yang secara keseluruhan terhubung. Namun, kedua lapisan tersebut masih mengoprasikan produk dot, sehinga fungsinya tidak begitu berbeda.
Dropout Regularization
Dropout adalah teknik regularisasi jaringan syaraf dimana beberapa neuron akan dipilih secara acak dan tidak dipakai selama pelatihan. Neuron-neuron ini dapat dibilang dibuang secara acak. Hal ini berarti bahwa kontribusi neuron yang dibuang akan diberhentikan sementara jaringan dan bobot baru juga tidak diterapkan pada neuron pada saat melakukan backpropagation.
Dropout merupakan proses mencegah terjadinya overfitting dan juga mempercepat proses learning. Dropout mengacu kepada menghilangkan neuron yang berupa hidden mapun layer yang visible di dalam jaringan. Dengan menghilangkan suatu neuron, berarti menghilangkannya sementara dari jaringan yang ada. Neuron yang akan dihilangkan akan dipilih secara acak. Setiap neuron akan diberikan probabilitas yang bernilai antara 0 dan 1.
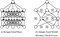

Pada gambar diatas jaringan syaraf (a) merupakan jaringan syaraf biasa dengan 2 lapisan tersembunyi. Sedangkan pada bagian (b) jaringan syaraf sudah diaplikasikan teknik regularisasi dropout dimana ada beberapa neuron aktivasi yang tidak dipakai lagi. Teknik ini sangat mudah diimplementasikan pada model CNN dan akan berdampak pada performa model dalam melatih serta mengurangi overfitting.
Pembelajaran Backpropagation
Salah satu sifat neural network yang menyerupai dengan otak manusia adalah bahwa neural network membutuhkan proses pembelajaran. Pembelajaran dilakukan untuk menentukan nilai bobot yang tepat untuk masing-masing input. Bobot bertambah jika informasi yang diberikan oleh neuron yang bersangkutan tersampaikan. Sebaliknya jika informasi tidak disampaikan maka nilai bobot berubah secara dinamis sehingga dicapai suatu nilai yang seimbang. Apabila nilai ini telah mampu mengindikasikan hubungan yang diharapkan antara input dan output, proses pembelajaran bisa dihentikan.
Backpropagation merupakan algoritma pembelajaran yang terawasi dan biasanya digunakan oleh perceptron dengan banyak lapisan untuk mengubah bobotbobot yang terhubung dengan neuron-neuron yang ada pada lapisan tersembunyi. Algoritma ini menggunakan error output untuk mengubah nilai bobot-bobotnya dalam arah mundur (backward). Untuk mendapatkan error ini, tahap perambatan maju (forward propagation) harus dikerjakan terlebih dahulu. Pada saat perambatan maju, neuron-neuron diaktifkan dengan menggunakan fungsi aktivasi yang dapat diturunkan, seperti fungsi sigmoid.
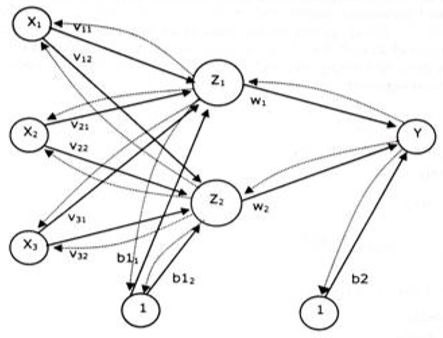
Arsitektur jaringan backpropagation seperti ditunjukkan pada dibawah ini. Gambar tersebut menunjukkan neural network yang terdiri dari tiga unit neuron pada lapisan input(x1, x2, dan x3), dua neuron pada lapisan tersembunyi(Z1 dan Z2), dan 1 unit neuron pada lapisan output (Y). Bobot yang menghubungkan x1, x2, dan x3 dengan neuron pertama pada lapisan tersembunyi adalah V11, V21, dan V31 . b11 dan b12 adalah bobot bias yang menuju neuron pertama dan kedua pada lapisan tersembunyi. Bobot yang mengubungkan Z1 dan Z2 dengan neuron pada lapisan output adalah w1 dan w2. Bobot bias b2 menghubungkan lapisan tersembunyi dengan lapisan output.
Confusion Matrix

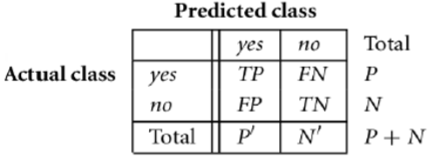
Pada gambar tersebut ditunjukkan, nilai true positive didefinisikan sebagai positive tupple yang diklasifikasikan dengan benar oleh model. True negative adalah negative tupple yang diklasifikasikan dengan benar oleh model. Sementara itu, false positive adalah negative tupple yang diklasifikasikan sebagai kelas positif oleh model. False negative adalah positive tupple yang diklasifikasikan sebagai kelas negatif oleh model klasifikasi. Berdasar confusion matrix pada gambar tersebut, kinerja model klasifikasi dapat dihitung.
Akurasi
Akurasi didefinisikan sebagai persentase dari data uji yang diklasifikasikan ke kelas yang benar. Akurasi dapat dinyatakan dalam persamaan berikut.

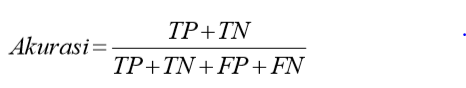
Selanjutnya, Implementasi Deep Learning Menggunakan Convolutional Neural Network Untuk Klasifikasi Gambar dengan R.





